· Tomasz Siroń · Technologia
Optymalizacja i diagnostyka warstw pierwszej oraz drugiej w infrastrukturze sieciowej przedsiębiorstwa - kompletny przewodnik dla personelu wsparcia IT
Utrzymanie stabilności sieci lokalnej (LAN) w środowisku firmowym stanowi fundament ciągłości procesów biznesowych. Dla personelu IT kluczowe znaczenie ma zrozumienie, że większość problemów zgłaszanych przez użytkowników jako „brak internetu” lub „wolne działanie aplikacji” ma swoje źródło w dwóch najniższych warstwach modelu OSI: fizycznej oraz łącza danych. Współczesne sieci firmowe, przechodzące ewolucję od prostych struktur opartych na urządzeniach niezarządzalnych w stronę zaawansowanych systemów opartych na przełącznikach zarządzalnych, wymagają specyficznej wiedzy diagnostycznej oraz dokumentacji infrastruktury IT.

Poniżej opisujemy najczęstsze patologie sieciowe, takie jak pętle przełączania, błędy konfiguracji prowadzące do zjawiska, jakim jest zatruwania arp oraz degradację sprzętową, dostarczając jednocześnie metodyki ich eliminacji.
Architektura i patologie warstwy fizycznej (L1)
Warstwa fizyczna jest często najbardziej pomijanym elementem diagnostyki, mimo że jej dysfunkcje generują najbardziej nieprzewidywalne objawy. W środowisku biurowym, gdzie infrastruktura kablowa jest narażona na uszkodzenia mechaniczne, a sprzęt sieciowy często pracuje w nieoptymalnych warunkach termicznych, degradacja komponentów pasywnych i aktywnych jest zjawiskiem powszechnym.
Stabilność łącza i zjawisko flappingu portów
Jednym z najbardziej uciążliwych problemów warstwy pierwszej jest tak zwany link flapping, czyli sytuacja, w której port przełącznika cyklicznie zmienia stan między aktywnym (Up) a nieaktywnym (Down). Przyczyną tego stanu rzeczy są najczęściej niskiej jakości przewody krosowe (patchcordy), które charakteryzują się mikrouszkodzeniami miedzianych żył lub źle zaciśniętymi wtykami RJ45. W takich przypadkach mechanizm autonegocjacji prędkości i dupleksu nie może osiągnąć stanu stabilnego, co skutkuje przerywaniem sesji użytkownika i koniecznością retransmisji pakietów na wyższych warstwach.

Skrętka komputerowa z wtykiem RJ45 wykorzystywania w sieciach LAN
Współczesne przełączniki zarządzalne pozwalają na monitorowanie liczby zmian stanu portu w logach systemowych, co jest pierwszym sygnałem dla technika IT, że dany odcinek okablowania wymaga wymiany. Warto zauważyć, że słaba jakość przewodu może nie powodować całkowitego zerwania połączenia, lecz generować błędy CRC (Cyclic Redundancy Check), które są widoczne w statystykach interfejsu jako pakiety odrzucone.
| Typ medium | Typowe przyczyny niestabilności | Wskaźniki w diagnostyce |
| Skrętka miedziana (UTP/STP) | Uszkodzenia mechaniczne, interferencje EM | Flapping portu, błędy CRC, niska prędkość linku |
| Światłowód wielomodowy (MM) | Zanieczyszczenie czółek ferul, mikrozgięcia | Wysoka tłumienność, błędy Rx/Tx na SFP |
| Moduły SFP/SFP+ | Przegrzanie, niekompatybilność firmware | Nagłe rozłączenia, brak rozpoznania modułu |
|
Uwaga! Podczas naprawy okablowania lub zarabiania wtyków RJ45 na kablach idących bezpośrednio do szafy Rack, należy bezwzględnie odłączyć przewód od przełącznika. Przecięcie kabla, który jest wpięty do działającego portu, powoduje zwarcie żył. Może to skutkować trwałym uszkodzeniem układu elektronicznego na porcie switcha lub wprowadzeniem go przez system w tryb administrative down (error-disable) w celu ochrony przed uszkodzeniem zasilania PoE. |
Degradacja komponentów elektronicznych i zasilania
Starzejąca się infrastruktura sprzętowa, szczególnie w przypadku urządzeń pracujących nieprzerwanie przez kilka lat, ulega procesom fizycznego zużycia komponentów elektronicznych. Najczęstszą przyczyną niestabilnej pracy starych przełączników są wyschnięte lub spuchnięte kondensatory elektrolityczne w sekcjach zasilania. Awaria tego typu objawia się w sposób bardzo subtelny przykładowo switch może działać poprawnie przy niskim obciążeniu, ale w momentach wzmożonego ruchu (np. podczas porannego logowania pracowników) następuje spadek napięcia na układach logicznych, co prowadzi do restartu urządzenia lub błędów w przetwarzaniu ramek.

Wyschnięte lub spuchnięte kondensatory to jedna z głównych przyczyn problemów niestabilności układów elektronicznych
Technik wsparcia powinien zwracać uwagę na nietypowe zachowanie diod statusowych – jeśli diody LED przygasają lub mrugają w sposób nieskoordynowany, może to sugerować problem z zasilaczem wewnętrznym. W przypadku przełączników zarządzalnych, logi mogą zawierać wpisy o niespodziewanych restartach (warm start/cold start) bez wyraźnej przyczyny administracyjnej.
Warstwa łącza danych (L2) i proces mapowania adresów IP na MAC (ARP)
Warstwa łącza danych (L2) odpowiada za przesyłanie ramek pomiędzy urządzeniami znajdującymi się w tej samej sieci lokalnej (LAN). W tej warstwie komunikacja odbywa się na podstawie adresów fizycznych MAC, które są unikalnymi identyfikatorami przypisanymi do kart sieciowych. Przełączniki sieciowe działające w tej warstwie podejmują decyzję o tym, na który port przekazać ramkę Ethernet, analizując właśnie adresy MAC nadawcy i odbiorcy. Z punktu widzenia infrastruktury sieciowej oznacza to, że zanim dane dotrą do właściwego urządzenia, muszą zostać poprawnie skierowane w obrębie lokalnej domeny przełączania.
Jednocześnie większość aplikacji oraz systemów operacyjnych identyfikuje urządzenia w sieci przy użyciu adresów IP, które należą do wyższej warstwy modelu sieciowego, czyli warstwy trzeciej (L3). W praktyce oznacza to, że komputer wysyłający dane do innego hosta w tej samej podsieci zna jego adres IP, ale aby faktycznie przesłać ramkę Ethernet w sieci lokalnej, musi ustalić, jaki adres MAC jest z nim powiązany. Innymi słowy, adres IP określa logiczną tożsamość urządzenia w sieci, natomiast adres MAC wskazuje fizyczne miejsce, do którego powinna zostać dostarczona ramka w warstwie drugiej.
Rolę mechanizmu łączącego te dwa światy pełni protokół ARP (Address Resolution Protocol). Działa on na styku warstwy drugiej i trzeciej modelu sieciowego i umożliwia odwzorowanie adresu IP na odpowiadający mu adres MAC. Gdy komputer chce wysłać dane do urządzenia w tej samej sieci, a nie zna jego adresu MAC, wysyła w sieci zapytanie rozgłoszeniowe ARP. Zapytanie to trafia do wszystkich urządzeń w danym segmencie sieci, a host posiadający wskazany adres IP odpowiada komunikatem zawierającym swój adres MAC. Informacja ta zostaje następnie zapisana w pamięci podręcznej ARP systemu operacyjnego, dzięki czemu kolejne pakiety mogą być wysyłane bez konieczności ponownego wykonywania procesu rozpoznawania adresu.
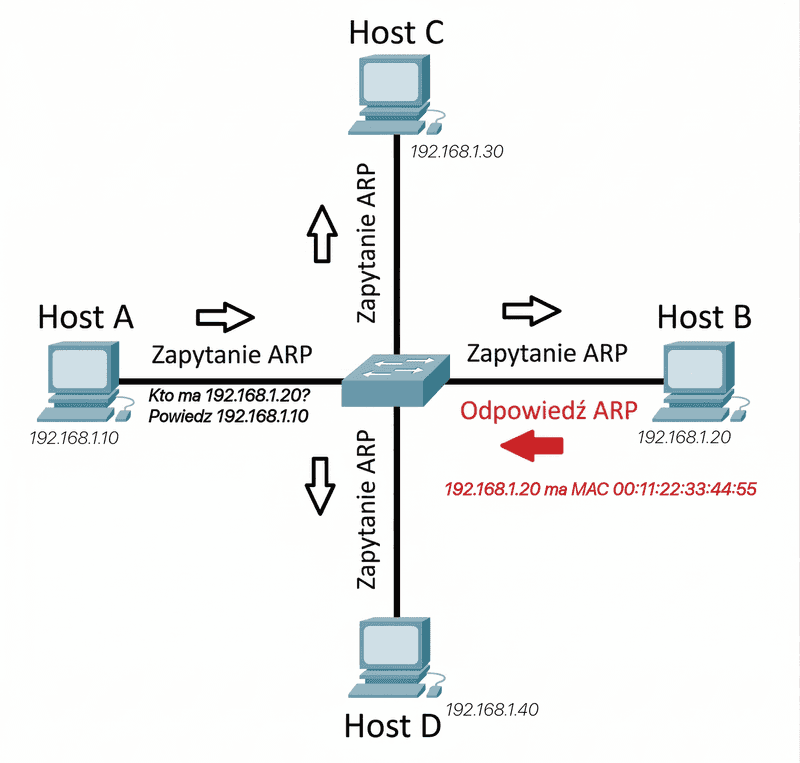 Schemat działania protokołu ARP
Schemat działania protokołu ARP
Z praktycznego punktu widzenia oznacza to, że wiele problemów, które użytkownicy lub technicy wsparcia interpretują jako błędy adresacji IP, w rzeczywistości wynika z nieprawidłowości w komunikacji warstwy drugiej lub z błędnych skojarzeń pomiędzy adresami IP i MAC. Jeśli host nie jest w stanie ustalić właściwego adresu MAC dla danego adresu IP, nie będzie w stanie dostarczyć ramki Ethernet do właściwego urządzenia, mimo że konfiguracja adresów IP może wyglądać poprawnie.
Dodatkową cechą protokołu ARP jest jego prostota. Protokół ten nie posiada mechanizmów uwierzytelniania ani weryfikacji źródła informacji, dlatego hosty w sieci zazwyczaj akceptują odpowiedzi ARP i aktualizują swoje wpisy w pamięci ARP bez dodatkowej kontroli. W normalnych warunkach upraszcza to komunikację w sieci lokalnej, jednak w pewnych sytuacjach może prowadzić do różnych anomalii. Mogą one wynikać z przypadkowych błędów konfiguracyjnych, takich jak konflikty adresów IP lub nieprawidłowe ustawienia urządzeń, ale również z celowych działań polegających na manipulowaniu odpowiedziami ARP, znanych jako ARP spoofing lub ARP poisoning. W rezultacie ruch sieciowy może zostać skierowany do niewłaściwego urządzenia, co prowadzi do problemów z łącznością, spadków wydajności lub potencjalnych zagrożeń bezpieczeństwa.
Mechanizm i skutki zatruwania ARP
W kontekście optymalizacji sieci, fraza zatruwania ARP odnosi się do manipulacji tablicą skojarzeń adresów IP i MAC. Protokół ARP nie posiada wbudowanych mechanizmów uwierzytelniania, co oznacza, że każde urządzenie w sieci zaakceptuje odpowiedź ARP (ARP Reply), nawet jeśli wcześniej o nią nie pytało. Zjawisko to jest nazywane Gratuitous ARP.

Przykład Gratuitous ARP widoczny w tcpdump - Host 192.168.1.10 wysłał zapytanie ARP o własny adres IP i natychmiast na nie odpowiedział.
Zatruwania ARP może wystąpić nieświadomie w wyniku błędnej konfiguracji stacji roboczych lub urządzeń sieciowych.
Częstym problemem jest sytuacja, w której wiele urządzeń ma ustawioną niepoprawną bramę domyślną. Urządzenia te, próbując skomunikować się ze światem zewnętrznym, wysyłają ciągłe zapytania ARP dla błędnego adresu IP. Jeśli w sieci znajduje się inne urządzenie (np. stary serwer lub źle skonfigurowana drukarka), które błędnie odpowiada na te zapytania, dochodzi do „zatrucia” lokalnych tablic ARP, co skutkuje przekierowaniem ruchu w „czarną dziurę”.
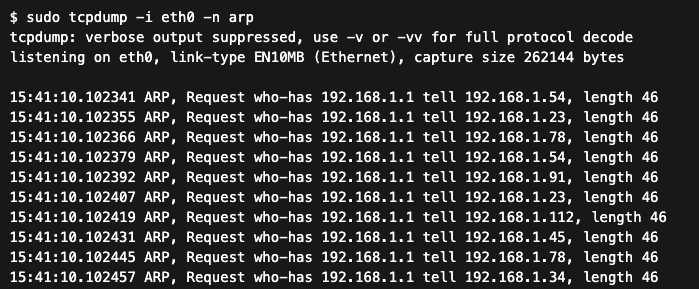
Przykładowy fragment ARP storm widoczny w tcpdump spowodowany błędną bramą domyślną. Wygląda to jak lawina zapytań ARP pojawiających się w bardzo krótkim czasie.
Skutki zatruwania ARP dla stabilności sieci:
-
Przerwy w łączności z Internetem dla wybranych segmentów sieci.
-
Nagłe spadki wydajności wynikające z konieczności ciągłego odświeżania tablic ARP przez hosty.
-
Możliwość przeprowadzenia ataków typu Man-in-the-Middle (MitM), gdzie napastnik przechwytuje dane przesyłane między użytkownikiem a bramą domyślną.
| Rodzaj zdarzenia ARP | Mechanizm działania | Wpływ na sieć |
| Standardowe zapytanie | "Kto ma adres IP X? Powiedz Y" | Niezbędne do normalnej pracy |
| Gratuitous ARP | Rozgłoszenie własnego adresu bez zapytania | Aktualizacja cache, może być użyte do ataku |
| ARP Poisoning (Zatruwanie) | Sfałszowana odpowiedź z MAC atakującego | Przechwycenie ruchu, przerwa w łączności |
| ARP Storm | Masowe generowanie zapytań przez błąd konfiguracyjny | Przeciążenie procesora przełącznika |
Problemy wydajnościowe tanich przełączników pod obciążeniem ARP
W praktyce wsparcia IT często zauważa się, że przełączniki niskiej klasy (tzw. smart switche lub urządzenia budżetowe) posiadają błędy w oprogramowaniu układowym, które ujawniają się przy zwiększonym ruchu rozgłoszeniowym. Pakiety ARP są z natury przesyłane jako broadcast, co oznacza, że przełącznik musi je powielić na wszystkie aktywne porty w danej sieci VLAN.
Tanie urządzenia często nie posiadają dedykowanych układów ASIC o wystarczającej wydajności do obsługi dużych ilości ruchu typu BUM (Broadcast, Unknown Unicast, Multicast). Przy standardowej, ale większej liczbie pakietów ARP – generowanych np. przez skanery sieciowe lub błędy w oprogramowaniu drukarek – procesor takiego przełącznika może zostać przesycony (CPU spikes). Skutkuje to tym, że switch „przestaje przepuszczać” pakiety ARP, mimo że zwykły ruch unicast (np. trwająca sesja FTP) wydaje się działać. Użytkownik widzi to jako sytuację, w której „raz sieć działa, a raz nie” – nowe połączenia nie mogą zostać nawiązane, ponieważ system operacyjny nie może uzyskać adresu MAC odbiorcy, podczas gdy istniejące połączenia oparte na zapisanym cache ARP nadal funkcjonują.
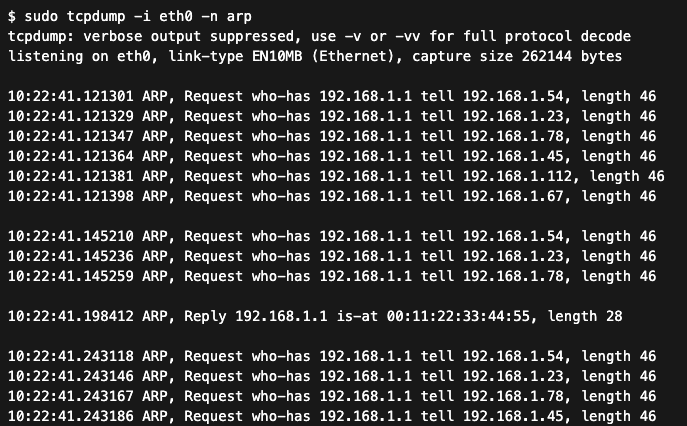
W analizie tcpdump przeciążenie taniego przełącznika często objawia się dużą liczbą zapytań ARP typu who-has, przy jednocześnie sporadycznych odpowiedziach is-at, co wskazuje na utratę pakietów broadcast przez przeciążony switch. Jest to bardzie podobne do burzy ARP spowodowanej konfiguracją błędnej bramy domyślnej
Patologie rozgłoszeniowe i pętle sieciowe
Sieć firmowa bez odpowiedniej filtracji ruchu rozgłoszeniowego jest podatna na zjawisko burzy rozgłoszeniowej (broadcast storm), która potrafi sparaliżować całą infrastrukturę w ciągu kilku sekund.

Przykład typowej sytuacji w sali konferencyjnej – po zakończonym spotkaniu użytkownik może przypadkowo podłączyć oba końce tego samego przewodu RJ45 do dwóch gniazd sieciowych w stole.
Pętle w salach konferencyjnych i ich eliminacja
Klasycznym problemem zgłaszanym przez administratorów jest sytuacja, w której użytkownik w sali konferencyjnej, chcąc posprzątać kable po spotkaniu, wpina oba końce tego samego przewodu RJ45 do gniazd na stole konferencyjnym, które są podłączone do tego samego przełącznika lub różnych przełączników w tej samej warstwie drugiej. W sieciach bez włączonego protokołu Spanning Tree (STP), ramka rozgłoszeniowa wprowadzona do takiej pętli zaczyna krążyć w niej w nieskończoność, powielając się przy każdym przejściu przez switch.
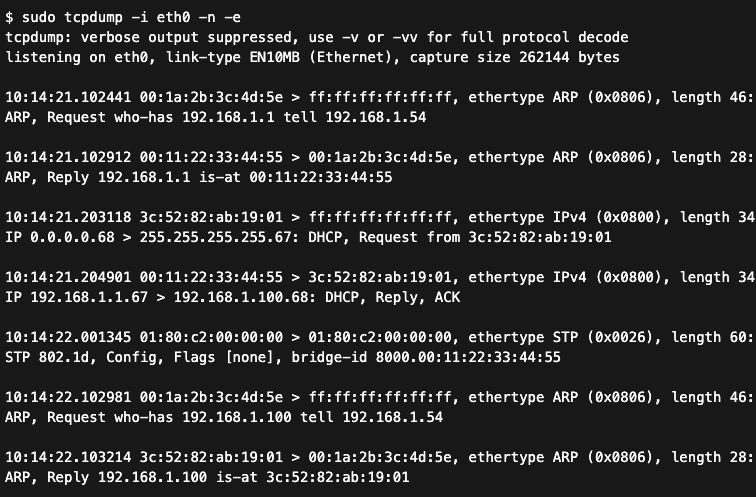
Logi z narzędzia tcpdump dokumentują wystąpienie pętli w sieci LAN, którą próbuje opanować protokół STP widoczny w warstwie łącza danych. Nienaturalnie wysoka częstotliwość i powtarzalność zapytań rozgłoszeniowych (ARP oraz DHCP) w milisekundowych odstępach czasu świadczy o trwającej burzy rozgłoszeniowej (broadcast storm).
Ponieważ ramki Ethernet nie mają licznika TTL (Time to Live), jedynym sposobem na zatrzymanie burzy jest fizyczne przerwanie pętli lub przeciążenie urządzenia do stanu awarii. W przełącznikach zarządzalnych standardem powinno być włączenie protokołu Rapid Spanning Tree (RSTP) oraz funkcji BPDU Guard na portach dostępowych. BPDU Guard automatycznie blokuje port, jeśli wykryje na nim ramkę zarządzającą BPDU, co sugeruje, że do portu podłączono inne urządzenie przełączające lub powstała pętla.
Sianie broadcastem przez urządzenia końcowe
Drukarki sieciowe, systemy monitoringu IP oraz niektóre urządzenia IoT często korzystają z protokołów Discovery (np. Bonjour, SSDP), które opierają się na intensywnym rozgłaszaniu pakietów. W przypadku awarii stosu sieciowego w takim urządzeniu, może ono zacząć generować tysiące pakietów na sekundę, co bez odpowiedniego filtrowania obciąża wszystkie stacje robocze w danej podsieci.
Rozwiązaniem wspieranym przez przełączniki zarządzalne jest funkcja Storm Control. Pozwala ona na zdefiniowanie progu (np. 1% przepustowości portu lub 100 pakietów na sekundę) dla ruchu typu broadcast i multicast. Po przekroczeniu tego progu przełącznik odrzuca nadmiarowe pakiety, chroniąc resztę sieci przed degradacją, przy jednoczesnym zachowaniu funkcjonalności urządzenia generującego ruch.
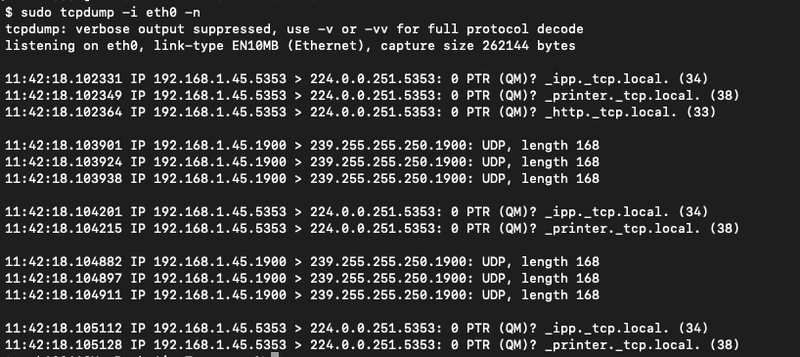
Fragment z tcpdump pokazujący drukarkę sieciową, która „sieje” broadcastami discovery (Bonjour / mDNS oraz SSDP). Widać bardzo częste pakiety multicast/broadcast wysyłane przez jedno urządzenie.
| Parametr STP | Wartość domyślna (802.1D) | Rola w zapobieganiu pętlom |
| Bridge Priority | 32768 | Wybór Root Bridge (im niższy, tym lepiej) |
| Hello Time | 2 sekundy | Częstotliwość wysyłania ramek BPDU |
| Max Age | 20 sekund | Czas przechowywania informacji o topologii |
| Forward Delay | 15 sekund | Czas oczekiwania przed przejściem w stan Forwarding |
Zagrożenia wynikające z nieautoryzowanych usług sieciowych
Pojawienie się w sieci firmowej urządzeń, które nie podlegają kontroli działu IT, stanowi jedno z największych wyzwań dla stabilności warstwy drugiej.
Prywatne routery i ataki Rogue DHCP
Pracownicy często przynoszą do biura prywatne routery Wi-Fi, które wpinają do gniazd sieciowych portami LAN, zamiast WAN. Skutkuje to uruchomieniem nieautoryzowanego serwera DHCP w sieci firmowej. Gdy nowa stacja robocza wysyła zapytanie o adres IP (DHCP Discover), dochodzi do wyścigu (race condition) między legalnym, firmowym serwerem DHCP a prywatnym routerem.
Protokół DHCP (Dynamic Host Configuration Protocol) służy do automatycznego przydzielania konfiguracji sieciowej urządzeniom w sieci lokalnej. Dzięki niemu komputer po podłączeniu do sieci otrzymuje nie tylko adres IP, ale również maskę podsieci, adres bramy domyślnej oraz serwery DNS. DHCP działa w warstwie siódmej, aplikacji modelu sieciowego i wykorzystuje protokół UDP w warstwie czwartej, transportowej (porty 67 i 68). W początkowej fazie komunikacji klient nie posiada jeszcze adresu IP, dlatego zapytania DHCP są wysyłane w formie rozgłoszeniowej (broadcast) w obrębie sieci lokalnej, co powoduje, że mechanizm ten silnie zależy od poprawnego działania infrastruktury warstwy drugiej. Proces przydzielania adresu przebiega automatycznie. Komputer wysyła zapytanie DHCP Discover, na które serwer DHCP odpowiada propozycją konfiguracji (DHCP Offer). Następnie klient potwierdza chęć użycia tej konfiguracji komunikatem DHCP Request, a serwer finalizuje proces odpowiedzią DHCP Ack. W prawidłowo skonfigurowanej sieci tylko jeden autoryzowany serwer DHCP odpowiada na takie zapytania.
Jeśli prywatny router odpowie szybciej, komputer użytkownika otrzyma adres IP z innej podsieci (często 192.168.0.x lub 192.168.1.x), wraz z błędną bramą domyślną i serwerami DNS. Użytkownik traci dostęp do zasobów wewnętrznych i Internetu, a diagnostyka problemu może być utrudniona, jeśli technik nie sprawdzi, jaki serwer DHCP przyznał adres (można to zweryfikować poleceniem ipconfig /all w polu DHCP Server).
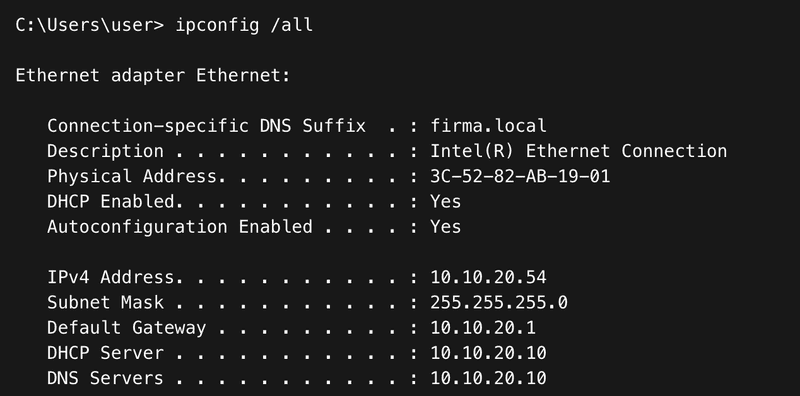
Poprawny DHCP – Windows – screen przykładowy
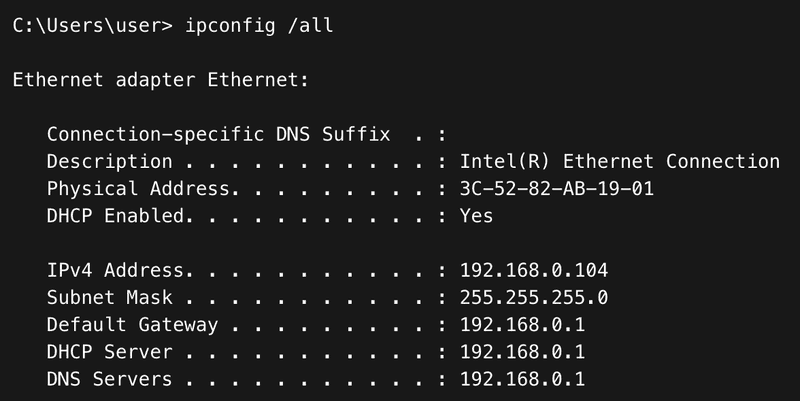
Błędny DHCP – prywatny router – screen przykładowy
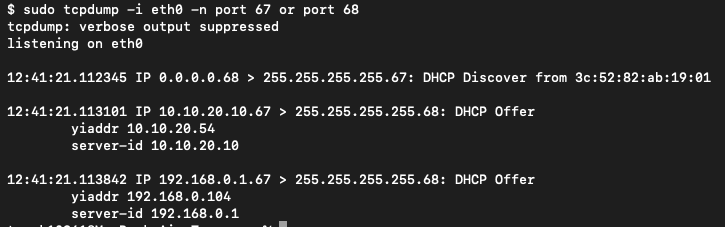
Wyścig DHCP widoczny w tcpdump
Metodą ochrony przed tym zjawiskiem jest DHCP Snooping. Funkcja ta na przełączniku zarządzalnym pozwala zdefiniować porty jako zaufane (trusted – tam, gdzie znajduje się prawdziwy serwer) oraz niezaufane (untrusted – wszystkie porty klienckie). Przełącznik odrzuca pakiety DHCP Offer i DHCP Ack przychodzące z portów niezaufanych, skutecznie neutralizując nieautoryzowane routery.
Konflikty adresów IP i ich diagnostyka
Konflikt IP występuje, gdy dwa urządzenia w tej samej sieci próbują używać tego samego adresu logicznego. W warstwie drugiej objawia się to ciągłym „skakaniem” wpisu w tablicy MAC przełącznika dla danego adresu IP. Powoduje to, że pakiety są dostarczane raz do jednego, raz do drugiego urządzenia, co uniemożliwia stabilną pracę.
Dla wsparcia IT przydatna jest możliwość szybkiego sprawdzenia powiązania adresów IP i MAC przy użyciu narzędzi dostępnych w systemie operacyjnym. W systemie Windows można wykorzystać polecenie arp -a, które wyświetla tablicę ARP komputera. Jeżeli podejrzewamy konflikt dla konkretnego adresu, np. 192.168.1.50, można najpierw wykonać ping 192.168.1.50, a następnie ponownie sprawdzić tablicę ARP. Jeżeli adres MAC przypisany do tego IP zmienia się pomiędzy kolejnymi odczytami, oznacza to, że dwa różne urządzenia odpowiadają na ten sam adres. W systemie Linux podobną diagnostykę można przeprowadzić poleceniem ip neigh lub arp -n.
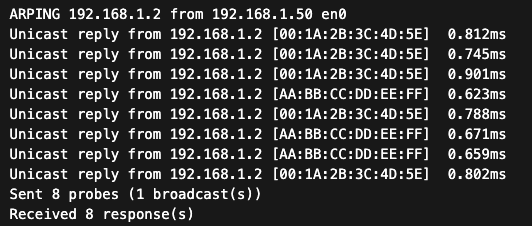
Przykład narzędzia ARP ping wraz z widocznym zdublowanym adresem IP rozwiązywanym na dwa różne fizyczne adresy MAC
Dla bardziej precyzyjnej diagnostyki można wykorzystać narzędzie arping, które wysyła zapytania ARP bezpośrednio w warstwie drugiej. Pozwala ono sprawdzić, jakie urządzenia odpowiadają na dany adres IP i czy pojawiają się odpowiedzi z różnych adresów MAC, co jest typowym objawem konfliktu adresów IP lub ataku ARP poisoning.
Metodyka diagnostyczna i narzędzia wsparcia
Skuteczne rozwiązywanie problemów w warstwach L1 i L2 wymaga systematycznego podejścia, eliminującego kolejne potencjalne przyczyny awarii.
Systematyka rozwiązywania problemów (Top-Down vs Bottom-Up)
Większość doświadczonych techników stosuje metodę Bottom-Up, zaczynając od sprawdzenia fizycznego połączenia. Jeśli dioda na karcie sieciowej się świeci, kolejnym krokiem jest weryfikacja parametrów warstwy łącza danych.
Diagnostyka krok po kroku:
-
Weryfikacja warstwy fizycznej: Sprawdzenie kabla, wymiana patchcordu na sprawdzony, weryfikacja czy port na switchu nie jest w stanie "error-disabled".
-
Analiza tablicy ARP: Użycie komendy arp -a. Jeśli brama domyślna ma nietypowy adres MAC lub ten sam MAC pojawia się przy wielu IP, należy podejrzewać zatruwania arp.
-
Weryfikacja DHCP: Sprawdzenie czy adres IP nie pochodzi z zakresu APIPA (169.254.x.x), co sugerowałoby problem z komunikacją w warstwie drugiej z serwerem DHCP.
-
Monitorowanie ruchu rozgłoszeniowego: Jeśli cała sieć działa wolno, należy odłączyć główne magistrale między przełącznikami i sprawdzać, czy problem ustępuje w poszczególnych segmentach (izolacja pętli)
Zaawansowana analiza z wykorzystaniem Wireshark
Gdy standardowe narzędzia systemowe nie pozwalają jednoznacznie zdiagnozować problemu, konieczne jest użycie sniffera pakietów. Najczęściej stosowane są narzędzia Wireshark oraz tcpdump, które umożliwiają analizę ruchu sieciowego na poziomie pojedynczych ramek Ethernet.
Wireshark oferuje graficzny interfejs i rozbudowane mechanizmy analizy protokołów. Pozwala m.in. na automatyczne wykrywanie anomalii w ruchu ARP, takich jak duplikaty odpowiedzi dla tego samego adresu IP. Program sygnalizuje takie zdarzenia w sekcji Expert Info, oznaczając je jako potencjalny konflikt adresów lub ARP poisoning.
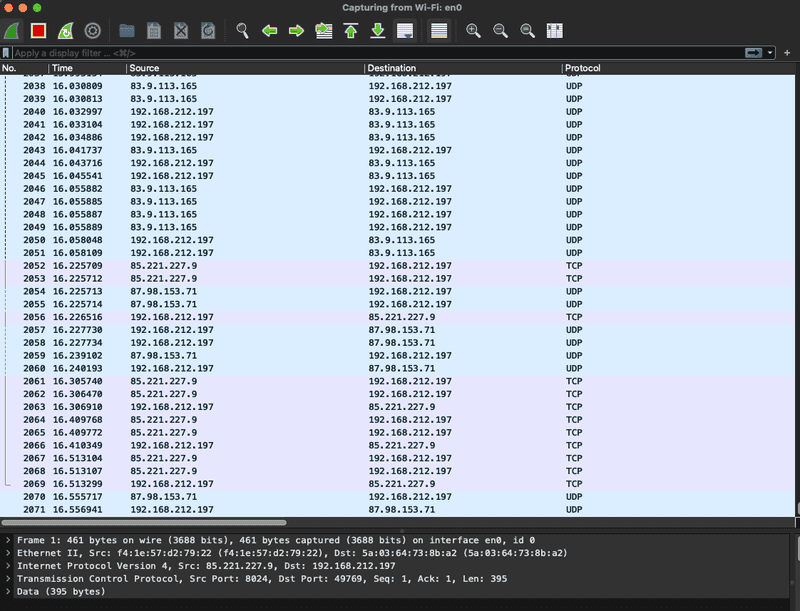
Zrzut przedstawia fragment przechwyconego ruchu sieciowego w narzędziu Wireshark, gdzie widoczna jest komunikacja pomiędzy stacją roboczą 192.168.212.197 a zewnętrznymi hostami z wykorzystaniem protokołów TCP i UDP.
W środowiskach serwerowych lub systemach Linux często używa się tcpdump, który umożliwia szybkie przechwycenie ruchu bez instalowania interfejsu graficznego.
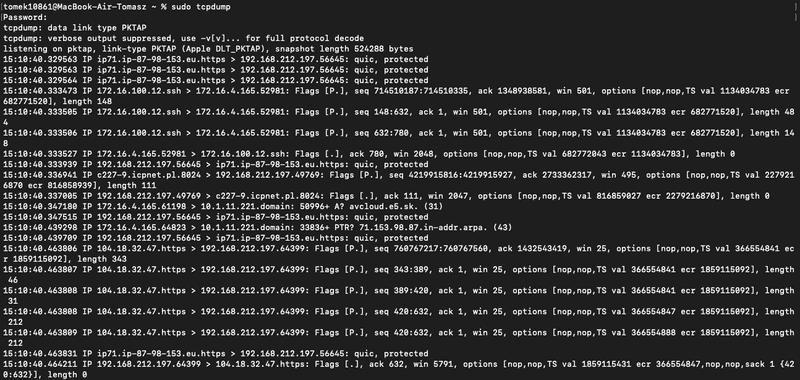
Na zrzucie przedstawiono przykładowy wynik działania narzędzia tcpdump, które przechwytuje ruch sieciowy bezpośrednio z interfejsu sieciowego.
Analiza ruchu ARP przy użyciu Wireshark lub tcpdump pozwala zidentyfikować między innymi:
-
Urządzenia skanujące sieć (duża liczba zapytań ARP Request w krótkim czasie).
-
Nieprawidłowe odpowiedzi ARP wysyłane przez urządzenia z błędną bramą domyślną.
-
Ruch generowany przez pętle (identyczne pakiety pojawiające się w odstępach mikrosekundowych).
| Narzędzie | Zastosowanie diagnostyczne | Korzyść dla wsparcia IT |
| ipconfig /all | Sprawdzenie adresu IP, maski i serwera DHCP | Szybka identyfikacja Rogue DHCP |
| arp -d * | Czyszczenie pamięci podręcznej ARP | Wymuszenie nowej rezolucji adresów |
| ping -t | Ciągły test osiągalności | Monitorowanie stabilności linku (flappingu) |
| show interfaces | Statystyki portu na przełączniku | Wykrywanie błędów CRC i kolizji |
| Wireshark lub tcpdump | Głęboka analiza protokołów | Wykrycie zatruwania ARP i burz rozgłoszeniowych |
Migracja do infrastruktury zarządzalnej
Dla firm rozważających migrację z przełączników niezarządzalnych na zarządzalne, kluczowym argumentem jest drastyczne skrócenie czasu usuwania awarii (MTTR - Mean Time To Repair). W sieci opartej na urządzeniach niezarządzalnych, znalezienie pętli w biurze o powierzchni 500 m2 może zająć godziny fizycznego odłączania kabli. W sieci zarządzalnej, administrator otrzymuje powiadomienie SNMP o zablokowaniu portu przez protokół STP w ciągu kilku sekund od wystąpienia incydentu
Zalety przełączników zarządzalnych w kontekście warstwy drugiej
Wdrożenie zarządzalnych rozwiązań pozwala na implementację mechanizmów obronnych, które czynią sieć odporną na błędy użytkowników i awarie sprzętu końcowego:
-
Segmentacja VLAN: Rozdzielenie ruchu gości, drukarek i stacji roboczych sprawia, że burza rozgłoszeniowa w jednym segmencie nie wpływa na pozostałe.
-
Limitowanie pasma (Rate Limiting): Ochrona przed urządzeniami „siejącymi” nadmiarowym ruchem.
-
Bezpieczeństwo portów (Port Security): Możliwość zablokowania portu po podłączeniu nieautoryzowanego urządzenia o nieznanym adresie MAC.
-
Zdalne zarządzanie: Możliwość restartu portu zasilającego urządzenie PoE (np. zawieszonej kamery lub punktu WiFi) bez konieczności fizycznej wizyty technika.
Przełączniki zarządzalne klasy enterprise (np. Cisco, Juniper, Aruba) oferują również zaawansowane mechanizmy ochrony procesora (Control Plane Policing), które zapobiegają zawieszaniu się urządzenia podczas masowych zapytań ARP, co jest częstą bolączką tanich modeli budżetowych.
Wnioski i rekomendacje dla personelu IT
Zapewnienie wysokiej dostępności sieci firmowej w warstwach pierwszej i drugiej wymaga nie tylko odpowiedniego sprzętu, ale przede wszystkim świadomej dyscypliny konfiguracyjnej. Personel wsparcia IT powinien traktować każde zgłoszenie o niestabilności łącza jako potencjalny symptom głębszych problemów strukturalnych.
Kluczowe wnioski z analizy patologii sieciowych:
-
Zjawisko zatruwania arp jest najczęściej wynikiem nieumyślnych błędów konfiguracyjnych (błędna brama domyślna) lub awarii stosu sieciowego w tanich urządzeniach końcowych, a nie tylko celowych ataków.
-
Fizyczna degradacja infrastruktury (okablowanie, kondensatory) manifestuje się błędami logicznymi, takimi jak retransmisje i flapping portów, co wymaga czujności przy analizie logów systemowych.
-
Pętle sieciowe są nieuniknione w środowiskach biurowych, dlatego wdrożenie protokołu Spanning Tree wraz z funkcją BPDU Guard na wszystkich portach dostępowych jest standardem krytycznym.
-
Zarządzalne przełączniki są niezbędnym narzędziem diagnostycznym, umożliwiającym izolację problemów takich jak Rogue DHCP czy burze rozgłoszeniowe, które w sieciach niezarządzalnych prowadzą do całkowitego paraliżu firmy.
Dla linii wsparcia Helpdesk priorytetem powinno być opanowanie narzędzi diagnostycznych takich jak skanery IP i analizatory protokołów, co w połączeniu z wiedzą o mechanizmach działania ARP i DHCP pozwala na błyskawiczną identyfikację źródła problemu i przywrócenie sprawności sieci bez konieczności eskalacji problemu do administratorów wyższego szczebla. Inwestycja w migrację do przełączników zarządzalnych jest w tym procesie krokiem milowym, zmieniającym reaktywne gaszenie pożarów w proaktywne zarządzanie dostępnością usług sieciowych. Jeśli w Twojej firmie problemy sieciowe wciąż rozwiązuje się metodą prób i błędów, to znak, że czas przejść na bardziej uporządkowane podejście.
SparkSome pomaga uporządkować środowisko IT, wdrożyć lepszą diagnostykę, dobrać odpowiednią infrastrukturę oraz ograniczyć ryzyko awarii, zanim drobny problem zamieni się w kosztowny przestój . Jeżeli chcesz zwiększyć stabilność swojej sieci i uporządkować obszar wsparcia IT, skontaktuj się ze SparkSome Venture. Pomagam firmom projektować, modernizować i utrzymywać infrastrukturę sieciową w sposób, który daje nie tylko sprawniejsze działanie, ale też większy spokój na co dzień
FAQ – Optymalizacja i diagnostyka warstw L1 i L2 w sieci firmowej
1. Od czego zacząć diagnostykę problemu z siecią?
Najpierw od warstwy fizycznej: sprawdź kabel, port switcha i urządzenie końcowe. Dopiero później analizuj ARP, DHCP i konfigurację sieci.
2. Użytkownik zgłasza, że „internet raz działa, raz nie”. Od czego zacząć?
- sprawdź diodę portu na switchu
- jeśli dioda gaśnie i zapala się co kilka sekund, to najczęściej problem z kablem lub wtykiem RJ45
3. Jak najszybciej sprawdzić kabel?
- podmień patchcord na nowy
- jeśli problem znika, poprzedni kabel był uszkodzony
4. Port działa, ale sieć jest wolna lub niestabilna. Co sprawdzić?
- sprawdź prędkość linku na porcie switcha
- jeśli zamiast 1 Gb/s pojawia się 100 Mb/s, kabel może być uszkodzony lub źle zaciśnięty
5. Port na switchu ciągle przechodzi Up/Down. Co zrobić?
- wymień patchcord
- przepnij kabel do innego portu switcha
- sprawdź, czy wtyk RJ45 nie jest luźny
Jeśli problem znika po zmianie portu, port switcha może być uszkodzony.
6. Jak sprawdzić, czy winna jest karta sieciowa komputera?
- podłącz inny komputer tym samym kablem do tego samego portu w switchu,
- jeśli działa poprawnie, problem jest w karcie sieciowej lub sterowniku pierwszego komputera
7. Światłowód działa niestabilnie. Co sprawdzić najpierw?
- wypnij patchcord światłowodowy
- wyczyść złącza optyczne alkoholem np. izopropanolem i chusteczka bezpyłową
- podłącz ponownie
Brudne złącza są częstą przyczyną problemów z transmisją.
Uwaga! Nigdy nie patrz w złącza światłowodowe! Może spowodować to trwałe uszkodzenie wzroku!
8. Switch losowo się restartuje. Co może być przyczyną?
Najczęstsze powody:
- przegrzewanie urządzenia
- uszkodzony zasilacz
- zużyte kondensatory w starszym sprzęcie
Sprawdź temperaturę urządzenia i logi restartów.
9. Jaka jest najprostsza zasada diagnostyki L1/L2?
Najpierw sprawdzaj elementy najłatwiejsze do wymiany:
- kabel
- port switcha
- urządzenie końcowe
Dopiero potem analizuj konfigurację sieci.
10. Co to jest ARP i dlaczego jest ważny?
ARP mapuje adres IP na adres MAC. Bez poprawnego ARP host nie znajdzie urządzenia w sieci lokalnej ani bramy domyślnej.
11. Dlaczego stare połączenia działają, a nowe nie?
Stare sesje korzystają z zapisanych wpisów w ARP cache. Jeśli ARP przestaje działać poprawnie, nowe połączenia nie mogą powstać.
12. Co oznacza, gdy dwa MAC odpowiadają na ten sam adres IP?
To zwykle oznacza:
- konflikt adresów IP
- błędną konfigurację urządzeń
- ARP poisoning
13. Czy Gratuitous ARP zawsze oznacza problem?
Nie. Może służyć do aktualizacji cache ARP lub przejęcia adresu IP w systemach HA. Problem zaczyna się wtedy, gdy takie pakiety pojawiają się nietypowo często albo z niewłaściwego urządzenia.
14. Dlaczego w tcpdump lub Wiresharku widać setki zapytań ARP o gateway?
Hosty próbują znaleźć MAC bramy. Przyczyny mogą być takie:
- router nie odpowiada
- błędna brama domyślna
- przeciążony switch
- pętla w sieci
15. Jak sprawdzić, czy problem dotyczy ARP?
Najprościej uruchomić analizę ruchu, np. w tcpdump lub Wiresharku. Jeśli widać dużo zapytań who-has bez odpowiedzi is-at, host nie może znaleźć urządzenia docelowego.
16. Dlaczego tanie switche czasem gubią sieć?
Duża liczba pakietów broadcast, np. ARP, może przeciążyć procesor taniego przełącznika. Objawy:
- dużo who-has
- bardzo mało is-at
17. Co to jest ARP storm?
To lawina zapytań ARP, zwykle spowodowana błędną konfiguracją, awarią urządzenia albo problemem z bramą domyślną.
18. Co to jest broadcast storm?
To sytuacja, gdy w sieci krąży bardzo dużo pakietów broadcast. Powoduje to spowolnienie lub całkowity brak komunikacji w sieci.
19. Jak powstają pętle w sieci?
Najczęściej przez przypadek. Na przykład ktoś podłącza oba końce jednego kabla RJ45 do dwóch gniazd sieciowych.
20. Jak wygląda pętla w tcpdump lub Wiresharku?
Widać te same pakiety broadcast, np. ARP lub DHCP, powtarzające się bardzo często w krótkich odstępach czasu.
21. Jak zabezpieczyć sieć przed pętlami?
Najważniejsze funkcje switcha:
- RSTP – wykrywa pętle i blokuje port
- BPDU Guard – blokuje port, gdy wykryje switch lub pętlę
- Storm Control – ogranicza ruch broadcast
22. Czy urządzenia końcowe mogą przeciążyć sieć?
Tak. Drukarki, kamery lub IoT mogą generować bardzo dużo pakietów discovery, np. Bonjour, SSDP lub mDNS. W przypadku błędu potrafią wysyłać tysiące pakietów na sekundę.
23. Dlaczego komputer dostaje adres 169.254.x.x?
To adres APIPA oznaczający, że komputer nie otrzymał konfiguracji z serwera DHCP. Najczęstsze przyczyny to brak komunikacji z DHCP, problem w warstwie drugiej (VLAN, port switcha) lub wyczerpana pula adresów DHCP.
24. Dlaczego nowe urządzenia nie dostają adresu IP, a stare działają normalnie?
Możliwą przyczyną jest wyczerpana pula DHCP. Serwer nie ma już wolnych adresów IP do przydzielenia nowym urządzeniom.
25. Jak sprawdzić, czy pula DHCP jest pełna?
Należy sprawdzić na serwerze DHCP listę dzierżaw (DHCP leases) oraz zakres adresów przypisanych do danej sieci. Jeśli wszystkie adresy są zajęte, nowe urządzenia nie otrzymają konfiguracji.
26. Jak rozwiązać problem wyczerpanej puli DHCP?
Można zwiększyć zakres adresów IP w konfiguracji DHCP, skrócić czas dzierżawy (lease time) lub usunąć nieaktywne wpisy z listy dzierżaw.
27. Co to jest Rogue DHCP?
To nieautoryzowany serwer DHCP w sieci, np. prywatny router pracownika, który rozdaje błędne adresy IP.
28. Jak rozpoznać Rogue DHCP?
Na komputerze sprawdź ipconfig /all i pole DHCP Server. Jeśli pokazuje adres prywatnego routera, masz źródło problemu.
29. Jak wygląda Rogue DHCP w tcpdump?
Na jedno zapytanie DHCP Discover widać więcej niż jedną odpowiedź DHCP Offer z różnych adresów IP.
30. Co robi DHCP Snooping?
Blokuje odpowiedzi DHCP z niezaufanych portów i chroni sieć przed nieautoryzowanymi routerami.
31. Jak rozpoznać konflikt adresów IP?
Ten sam adres IP zaczyna być kojarzony z różnymi adresami MAC, a komunikacja działa niestabilnie lub losowo.
32. Jakie narzędzia powinien znać technik pierwszej linii wsparcia IT?
Minimum:
ipconfig /allarp -aping- Wireshark
- Tcpdump
33. Kiedy użyć Wiresharka, a kiedy tcpdump?
Wireshark jest wygodniejszy do analizy graficznej np. na komputerze użytkownika, a tcpdump szybszy do przechwytywania ruchu bezpośrednio na serwerze lub w terminalu.
34. Jakie są największe zalety switchy zarządzalnych?
Pozwalają wykrywać pętle, ograniczać broadcast, blokować Rogue DHCP, analizować błędy portów i szybciej lokalizować źródło awarii.
35. Czy migracja do switchy zarządzalnych naprawdę ma sens?
Tak, bo skraca czas diagnozy, ogranicza skutki błędów użytkowników i pozwala przejść od reaktywnego gaszenia pożarów do proaktywnego utrzymania sieci.