· Tomasz Siroń · Technologia
Rozproszony klaster Proxmoxa z routingiem OSPF
Dlaczego budujemy własne środowisko wirtualizacyjne?
W naszej firmie SparkSome prowadzimy wiele szkoleń technicznych, m.in. pod marką Spark Academy. Uczymy administracji systemami Linux, automatyzacji (Ansible, GitLab CI/CD), wirtualizacji (Proxmox) oraz konteneryzacji (Docker i Kubernetes). Często równolegle odbywa się kilka kursów, a na każdym kilkunastu uczestników potrzebuje po 2–3 maszyny. W efekcie mamy niezły tłum wirtualnych gości – a to z kolei generuje konkretne potrzeby sprzętowe.
Na początku korzystaliśmy z jednego serwera dedykowanego w OVH. Rozwiązanie proste i szybkie, ale... nie do końca elastyczne. Czasem cały serwer stał bezczynnie, innym razem brakowało mocy – a abonament trzeba było płacić. Do tego – nie ukrywam – osobiście mam słabość do fizycznego sprzętu i grzebania w kablach. Dlatego decyzja była prosta... Budujemy własną infrastrukturę on-prem!

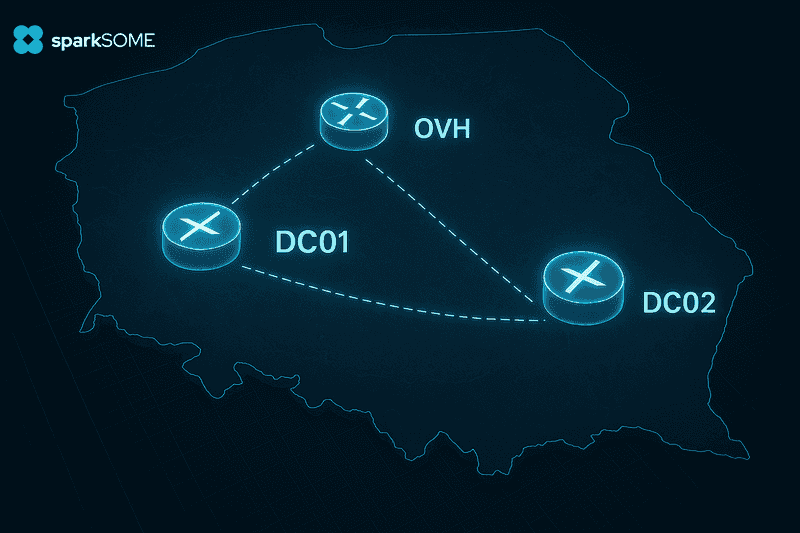
Obecnie nasz klaster Proxmoxa składa się z pięciu fizycznych maszyn rozproszonych między dwie lokalizacje. Każda z nich działa w osobnej podsieci warstwy trzeciej (L3), a komunikacja między nimi odbywa się przez klasyczny routing. Dla bezpieczeństwa, pomiędzy lokalizacjami zestawiliśmy tunel VPN oparty o WireGuarda – lekko, bezpiecznie i bezboleśnie.
Skąd wziąć tanie i elastyczne IPv4?
Własna infrastruktura to jedno, ale każdy, kto próbował zestawić rozsądnie działający klaster rozproszony po dwóch lokalizacjach, prędzej czy później zderza się z pytaniem, skąd wziąć publiczne IP i to najlepiej nie za miliony monet?
Tzw. klasyczny internet biurowy, z którego korzystamy w obu lokalizacjach, ma swoje ograniczenia — przede wszystkim brak możliwości dokupienia większej puli dedykowanych adresów IPv4. Nawet jeśli coś się uda zdobyć, to niekoniecznie chcemy z takich adresów korzystać. Łatwo po nich określić, że to biuro (a może nawet które!), co może zachęcać do skanowania całej puli. A i o sensownych zabezpieczeniach przed DDoS-em można zapomnieć — bo ich zwyczajnie nie ma.
Potrzebowaliśmy więc czegoś, co zepnie ruch IPv4 w tunel, a na jego końcu — w bezpiecznym i kontrolowanym środowisku — pozwoli nam wygodnie podpiąć publiczne IP do routera. Czyli, potrzebny był wydajny punkt końcowy tunelu, najlepiej z możliwością pełnej kontroli nad routingiem.
Rozwiązanie? Mały VPS w OVH.

Za około 20 zł netto miesięcznie (plus 7 zł za każde dodatkowe IP), można postawić VPS z serii VLE-2 — 2 rdzenie vCPU, 2 GB RAM, 40 GB NVMe i 0,5 Gbps bez limitu transferu. Problem w tym, że OVH nie udostępnia oficjalnie żadnych systemów routerowych do instalacji, takich jak Mikrotik CHR.
Ale na szczęście jest na to sposób. OVH oferuje tzw. rescue mode — czyli możliwość uruchomienia maszyny z tymczasowego systemu Linux. Wystarczy pobrać obraz CHR z poziomu wget, a potem nadpisać dysk VPS-a prostym poleceniem dd.

W naszym przypadku wyglądało to tak:
wget https://download.mikrotik.com/routeros/7.14.3/chr-7.14.3.img
dd if=chr-7.14.3.img of=/dev/sdb bs=4M status=progress
Po restarcie maszyny VPS uruchamia się z MikroTik Cloud Hosted Router — gotowy do pracy.
Czy OVH się o to obraża? Sprawdziliśmy. Oficjalna odpowiedź z supportu była jasna:
OVHcloud nie rekomenduje ani nie wspiera tego typu instalacji na serwerze VPS, ponieważ dysponujemy własną pulą oficjalnych templatek do instalacji systemu operacyjnego na serwerach wirtualnych. Jednakże nie jest to operacja zabroniona, ani wbrew zasadom firmy i nie będzie się wiązać z żadnymi konsekwencjami.
Efekt? Za niespełna 30 zł miesięcznie mamy własny router CHR z możliwością przypisania wielu zewnętrznych IP i dość sensowną przepustowością rzędu 0,5 Gbps. Stabilnie, przewidywalnie i w pełni pod naszą kontrolą.
Routing między lokalizacjami i przypisywanie publicznych adresów
Na początku nasza infrastruktura funkcjonowała wyłącznie w jednej lokalizacji, co upraszczało całą koncepcję routingu. Dla każdej podsieci projektowej tworzyliśmy osobny VLAN (zwykle w zakresie /24), a centralnym punktem zarządzającym ruchem był router uruchomiony na VPS-ie w OVH. Dzięki temu, że wszystkie maszyny znajdowały się w jednej podsieci L2, a do OVH wystarczył prosty routing statyczny, bez konieczności wdrażania dynamicznych protokołów.
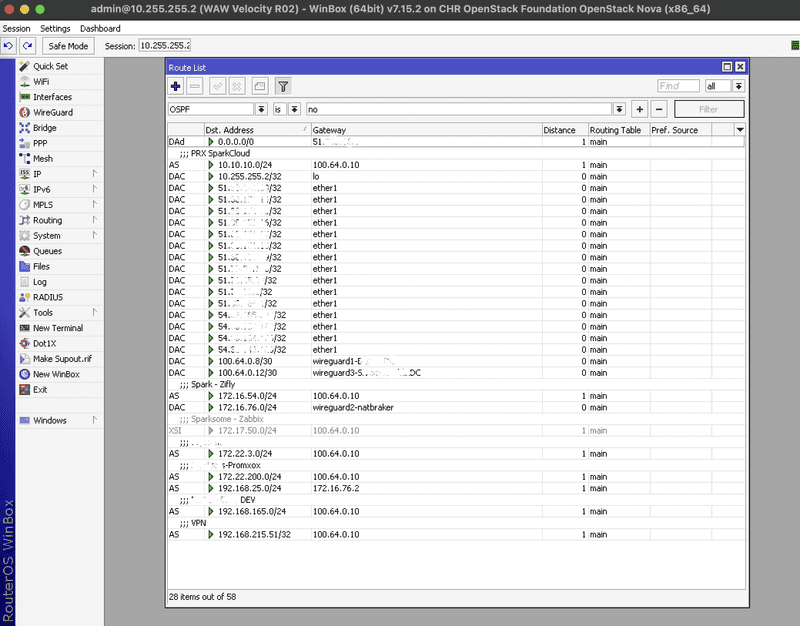
Ruch między lokalną siecią a światem zewnętrznym był zestawiany przez tunel VPN oparty o WireGuard. Zdecydowaliśmy się na to rozwiązanie ze względu na kilka kluczowych zalet:
- bardzo prostą konfigurację w porównaniu do klasycznego IPsec,
- wysoką stabilność działania nawet przy słabszym łączu,
- brak konieczności posiadania publicznego IP po obu stronach – wystarczyło jedno w OVH,
- możliwość pracy przez NAT,
- brak dużych wymagań sprzętowych (co istotne w przypadku użycia Mikrotik CHR, które nie mają wsparcia sprzętowego dla IPsec).
Tunel VPN działał jako kanał do komunikacji między naszą prywatną infrastrukturą a punktem końcowym w chmurze. To właśnie na routerze w OVH realizowaliśmy zarówno DNAT, jak i SNAT, co pozwalało przypisać konkretne publiczne IP do poszczególnych maszyn — zupełnie jak w środowiskach chmurowych typu AWS, Azure czy GCP.
W przypadku pełnego mapowania (tzw. 1:1 NAT), gdzie maszyna wewnętrzna ma przypisane jedno konkretne IP publiczne dla całego swojego ruchu, reguły na routerze wyglądały następująco:
/ip firewall nat
# Ruch przychodzący - pełne przekierowanie całego IP do maszyny wewnętrznej
add chain=dstnat action=dst-nat in-interface=ether1 dst-address=PUBLIC.IP.1 to-addresses=192.168.100.10 comment="Pełne DNAT"
# Ruch wychodzący - maszyna wewnętrzna korzysta z przypisanego publicznego IP
add chain=srcnat action=src-nat out-interface=ether1 src-address=192.168.100.10 to-addresses=PUBLIC.IP.1 comment="Pełne SNAT"
W sytuacjach, gdy chcieliśmy wystawić tylko wybrane usługi (np. HTTP, HTTPS, SSH) i nie przekazywać całego IP, stosowaliśmy selektywne przekierowania portów:
/ip firewall nat
# HTTPS
add chain=dstnat action=dst-nat in-interface=ether1 dst-address=PUBLIC.IP.2 dst-port=443 protocol=tcp to-addresses=192.168.100.11 to-ports=443 comment="HTTPS"
# HTTP
add chain=dstnat action=dst-nat in-interface=ether1 dst-address=PUBLIC.IP.2 dst-port=80 protocol=tcp to-addresses=192.168.100.11 to-ports=80 comment="HTTP"
# SSH przez niestandardowy port (np. 53293 → 22)
add chain=dstnat action=dst-nat in-interface=ether1 dst-address=PUBLIC.IP.2 dst-port=53293 protocol=tcp to-addresses=192.168.100.11 to-ports=22 comment="SSH niestandardowy port"
# Ruch wychodzący tylko z jednego źródła
add chain=srcnat action=src-nat out-interface=ether1 src-address=192.168.100.11 to-addresses=PUBLIC.IP.2 comment="SNAT selektywny"
Dzięki temu możliwe było przypisywanie jednego IP do wielu maszyn w zależności od potrzeb i usług, jakie dana maszyna miała świadczyć. Całość była w pełni kontrolowana przez router Mikrotik i mogła być łatwo rozszerzana w miarę wzrostu potrzeb. To podejście zapewniało wygodę i elastyczność znaną z chmur publicznych, jednocześnie pozostając w pełni pod naszą kontrolą.
Pożegnanie z L2 – czyli jak VXLAN prawie nas przekonał
Wszystko działało dobrze, dopóki infrastruktura mieściła się w jednej lokalizacji. Ale gdy do gry weszła druga lokalizacja, zaczęły się schody. Samo spięcie lokalizacji nie było problemem — dorzuciliśmy kolejne instancje WireGuarda i utworzyliśmy coś na kształt pierścienia:
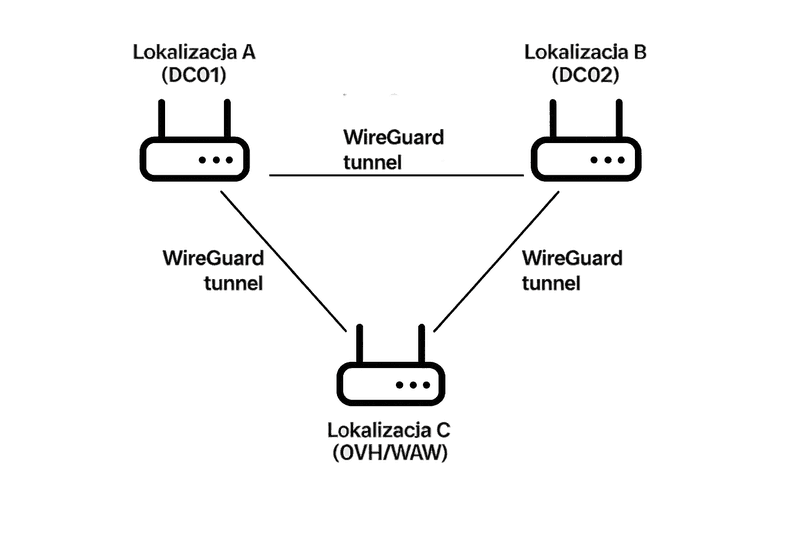
- Lokalizacja A (DC01) miała tunel z lokalizacją B (DC02) oraz z OVH (C),
- Lokalizacja B (DC02) była połączona z OVH (C) oraz z lokalizacją A (DC01),
- Lokalizacja C (OVH/WAW) miała tunel z lokalizacją A (DC01) oraz z lokalizacją B (DC02).
W efekcie każdy z każdym rozmawiał bezpośrednio. Teoretycznie sytuacja idealna, pełny mesh. Tyle że wtedy pojawiła się pokusa, skoro mamy pełną komunikację, to może pociągnijmy sieć warstwy drugiej (L2) i będziemy traktować to jak jedną, rozproszoną fizycznie lokalizację?
Pierwszy wybór padł na VXLAN (Virtual Extensible LAN) – protokół enkapsulujący ramki Ethernet w pakietach UDP, pozwalający „rozciągać” L2 przez L3, czyli przez Internet. W teorii – super. W praktyce – mniej.
Główna zaleta VXLAN-a to możliwość stworzenia izolowanych domen broadcastowych ponad istniejącą infrastrukturą IP. Idealne do tworzenia overlay network w środowiskach chmurowych czy data center. Jednak w naszym przypadku zaczęły się problemy:
- każdy tunel VXLAN musiałby zostać zdefiniowany per VLAN, ponieważ klasyczny VXLAN nie przenosi tagów VLAN bez dodatkowych zabiegów,
- przy topologii „każdy z każdym” oznaczałoby to eksplozję konfiguracji — z każdej lokalizacji do każdej innej potrzebne byłyby osobne tunele,
- do tego dochodzi bridgeowanie interfejsów, co w połączeniu z wieloma końcówkami generuje problemy ze spójnością domen rozgłoszeniowych,
- bez wdrożenia mechanizmu typu STP (Spanning Tree Protocol) istniało realne ryzyko powstania pętli w sieci — a wiadomo, jedna pętla i cała sieć idzie na kolana,
- z kolei STP nie współpracuje dobrze z VXLAN w topologii full mesh, więc byłoby to ryzykowne, trudne w debugowaniu i podatne na błędy,
- nie wspominając o tym, że wiele systemów nie wspiera STP na interfejsach VXLAN bez dodatkowych konfiguracji.
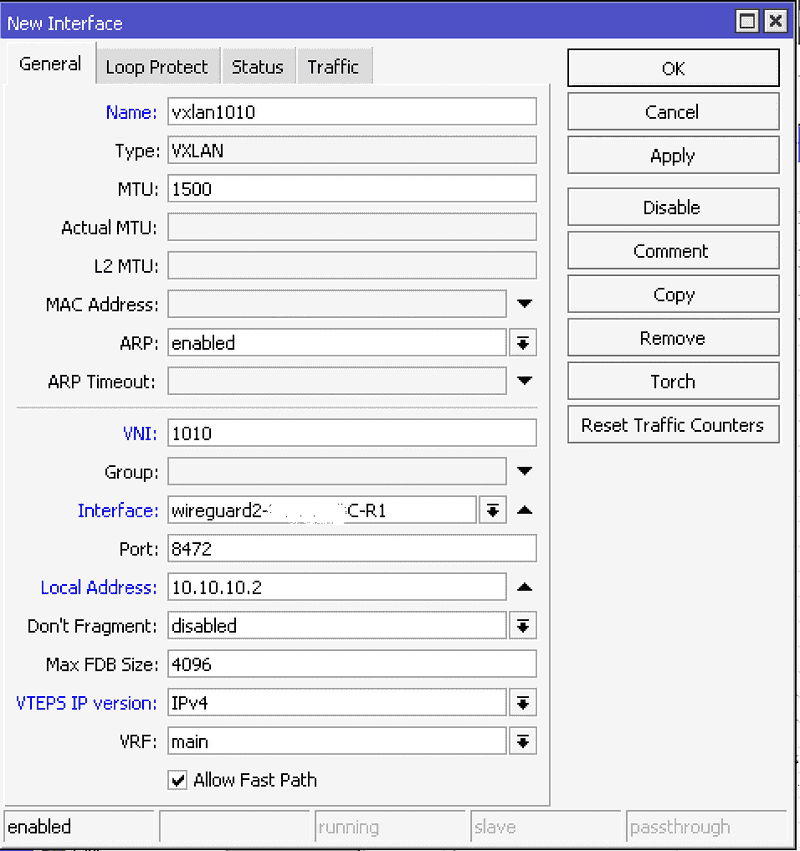
Teoretycznie mogliśmy to obejść – np. wymusić, by cały ruch szedł tylko przez router w OVH, rezygnując z bezpośrednich połączeń między lokalizacjami. Ale to byłoby mało eleganckie rozwiązanie. Dlaczego?
W takiej sytuacji cała komunikacja między maszynami w różnych lokalizacjach musiałaby przechodzić przez OVH — niepotrzebnie obciążając łącze, zwiększając opóźnienia i tworząc pojedynczy punkt awarii. Po prostu bez sensu.
Wniosek był jeden, czas pożegnać się z L2 i przejść na L3 z pełnoprawnym routingiem między lokalizacjami.
Routing z OSPF – elegancki szkielet całej infrastruktury
Skoro pożegnaliśmy się z L2 i topologią bridge’owaną przez VXLAN, nadszedł czas na coś, co po prostu działa — czyli pełnoprawny routing dynamiczny w warstwie trzeciej. Wybór padł na OSPF (Open Shortest Path First) – sprawdzony i dojrzały protokół, który świetnie radzi sobie z rozproszonym środowiskiem, a przy odpowiedniej segmentacji pozwala utrzymać porządek nawet w złożonej infrastrukturze.
Podstawowa koncepcja była prosta:
- każdy projekt lub grupa maszyn dostaje swój VLAN,
- adresacja wewnątrz VLAN-u to /30 – czyli dokładnie dwa adresy, jeden dla routera, drugi dla maszyny wirtualnej,
- każdy VLAN to osobna podsieć, dzięki czemu routing jest maksymalnie przejrzysty,
- wszystkie interfejsy L3 z VLAN-ów (np.
vlan2301,vlan2302...) są publikowane w OSPF przezinterface-template, - komunikacja między lokalizacjami leci dedykowanymi tunelami WireGuard (np.
100.64.0.8/30,100.64.0.12/30,100.64.0.20/30) – każda lokalizacja ma swoją osobną, fizycznie wydzieloną ścieżkę, - każdy z routerów ma zdefiniowany własny unikalny adres /32 na loopback.
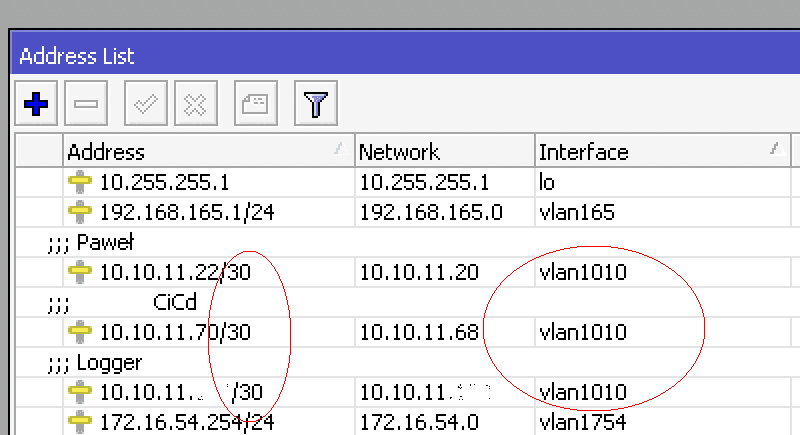
Dzięki takiemu podejściu, infrastruktura jest modułowa i łatwa do zarządzania. Gdy potrzebujemy dodać nową maszynę (np. w ramach szkolenia lub projektu), wystarczy:
- Dodać nowy adres /30 na interfejs VLAN,
- Przypisać odpowiedni adres IP na maszynie wirtualnej,
- Dodać linię
networks=X.X.X.X/30wrouting ospf interface-template.
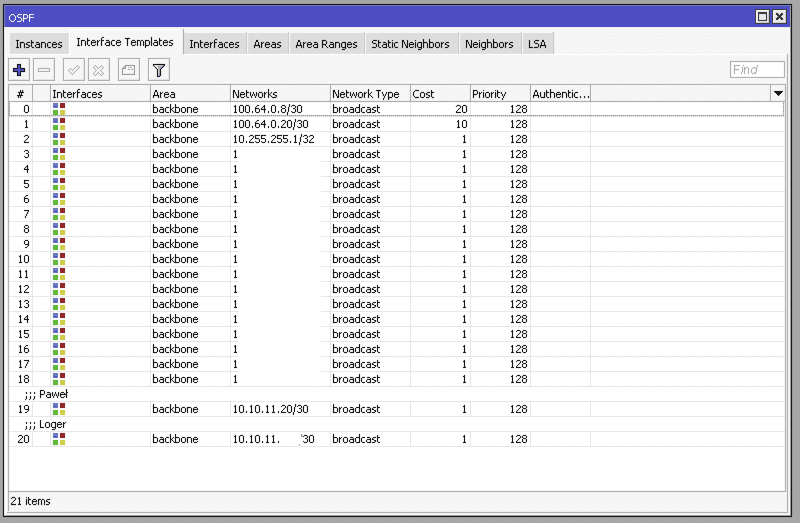
I to wszystko – maszyna staje się częścią sieci, trasy rozgłaszają się automatycznie do wszystkich routerów, a komunikacja działa natychmiast.
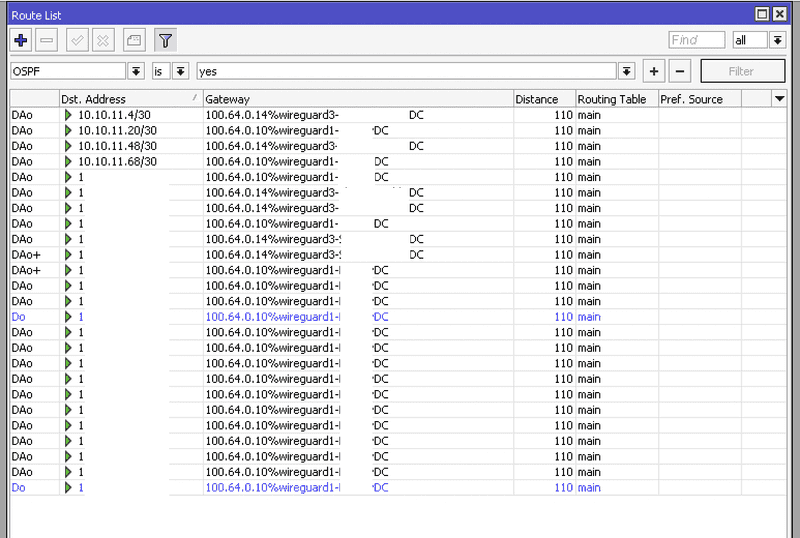
Dedykowane tablice routingu dla VM-ek
Aby dodatkowo uporządkować ruch wychodzący z maszyn wirtualnych, wprowadziliśmy mechanizm dedykowanych tablic routingu. Kluczowe założenie:
- VM-ki wychodzą do Internetu wyłącznie przez OVH,
- Routery korzystają ze swoich lokalnych łącz (np. Inea, Netia).
W praktyce realizowane jest to przez osobną tablicę routingu:
/routing table
add fib name=from-vmki
W tej tablicy umieszczana jest domyślna trasa przez tunel WireGuard do OVH:
/ip route
add dst-address=0.0.0.0/0 gateway=100.64.0.9 routing-table=from-vmki
Następnie na podstawie źródłowego adresu IP ruch jest kierowany do tej tablicy:
/routing rule
add action=lookup disabled=no dst-address=10.0.0.0/8 src-address=10.10.0.0/16 table=main
add action=lookup-only-in-table disabled=no dst-address=0.0.0.0/0 src-address=10.10.0.0/16 table=from-vmki
add action=lookup-only-in-table dst-address=0.0.0.0/0 src-address=172.22.0.0/16 table=from-vmki
add action=lookup-only-in-table disabled=no dst-address=0.0.0.0/0 src-address=192.168.165.0/24 table=from-vmki
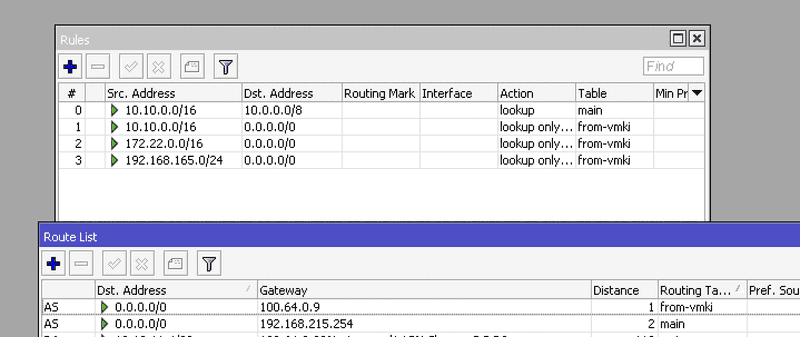
W ten sposób:
- maszyny z podsieci VM-ek zawsze wychodzą do Internetu przez tunel WireGuard → OVH (
100.64.0.9) → publiczne IP przypisane na CHR, - router nadal korzysta z lokalnego łącza (np.
192.168.215.0/24) do własnej komunikacji (np. tunele WireGuard), administracji czy monitoringu.
To rozwiązanie jest czytelne, bezpieczne i przewidywalne. Każdy element ruchu w sieci można rozdzielić, kontrolować i analizować. W połączeniu z OSPF i adresacją /30 per VLAN daje to pełen porządek sieciowy, z którym nie sposób się pogubić — nawet w międzylokacyjnym środowisku z kilkudziesięcioma usługami i VM-kami.
Podsumowanie
Rozproszone środowisko wirtualizacyjne oparte o Proxmoxa, CHR Mikrotika i WireGuard może być nie tylko wydajne, ale też wyjątkowo czyste logicznie i łatwe w utrzymaniu — o ile dobrze zaprojektuje się fundamenty sieciowe.
Zamiast walczyć z ograniczeniami L2, postawiliśmy na czytelny model warstwy trzeciej L3 z dynamicznym routingiem OSPF, gdzie:
- każdy projekt ma osobny VLAN i podsieć /30,
- adresacja jest jednoznaczna — router i VM to zawsze dwa konkretne IP,
- trasy propagują się automatycznie, a dodanie nowej maszyny to trzy kliknięcia, adresacja, VLAN i wpis w
interface-template, - dedykowane tunele WireGuard spinają lokalizacje fizycznie,
- VM-ki wychodzą do Internetu przez OVH, a routery korzystają ze swoich lokalnych uplinków – wszystko dzięki osobnym tablicom routingu.
Dodatkowo, dzięki wykorzystaniu klastra Proxmoxa, możemy korzystać z jednej z jego najmocniejszych funkcji — live migration. VM-ka działająca w jednej lokalizacji może być bez przerywania pracy przeniesiona do innej — o ile tylko ma tam przypisany odpowiedni VLAN i adresacja znajduje się w OSPF. To otwiera ogromne możliwości:
- balansowanie obciążenia między lokalizacjami,
- awaryjna ewakuacja maszyn z jednego DC,
- dynamiczne dostosowanie środowiska do szkoleń lub projektów klientów.
Co więcej — migracja maszyny między fizycznymi DC ogranicza się do kilku kliknięć w interfejsie Proxmoxa i ewentualnej korekty adresu IP. Resztę zrobi routing.
Najczęściej zadawane pytania (FAQ)
1. Czy nie dało się tego zrobić w L2 z bridge’ami i VXLAN-em?
Teoretycznie tak, ale praktycznie... to byłby koszmar. Przy topologii full-mesh szybko pojawiają się pętle, problemy z broadcastami, brak STP w VXLAN, potrzeba osobnych tuneli per VLAN i brak możliwości prostej separacji. Routing L3 to przejrzystość, skalowalność i lepsza kontrola.
2. Dlaczego VLAN-y mają adresację /30? To marnowanie adresów!
Nie marnujemy — zyskujemy porządek. Jeden VLAN to jeden projekt. Adresacja /30 daje dwa hostowalne adresy pod router i maszynę wirtualną. Każda podsieć jest jednoznaczna i izolowana. Debug? Błyskawiczny. Adres sieci i rozgłoszeniowy (czyli te dwa, o których „marnotrawstwo” można nas posądzić) nie stanowią problemu — maszyny i tak korzystają z prywatnej klasy adresowej.
3. Czemu OSPF, a nie BGP?
Bo to nie Internet, tylko sieć wewnętrzna. OSPF działa szybciej, prościej i automatycznie — nie trzeba ustawiać prefiksów, community ani polityk routingu. BGP zostawiamy dla ISP.
4. Jak działa routing między lokalizacjami Proxmoxa?
Między lokalizacjami zestawione są tunele WireGuard (/30). Adresy są publikowane w OSPF. Komunikacja odbywa się z pełną kontrolą metryk, a każda trasa może być priorytetyzowana. Działa to szybko i niezawodnie.
5. Czy są problemy z MTU przy tunelach WireGuard?
Nie. WireGuard domyślnie ustawia MTU 1420 i w praktyce wystarcza to do większości zastosowań. Nie zaobserwowaliśmy problemów przy protokołach TCP, UDP, SSH, NFS ani migracjach VM.
6. Czy WireGuard wpływa na wydajność klastra Proxmox?
Minimalnie. Testy pokazują praktycznie zerowy overhead CPU. Transfery leciały linią 1:1 z fizycznym interfejsem. WireGuard świetnie sprawdza się nawet na maszynach wirtualnych (np. CHR Mikrotik).
7. Czy routing dynamiczny obciąża routery Mikrotik CHR?
Nie zauważyliśmy problemów. Nawet przy kilkudziesięciu podsieciach i wielu tunelach CHR Mikrotik radzi sobie bez zająknięcia — zarówno w routingu, jak i NAT-ach.
8. Jakie są opóźnienia między lokalizacjami przez WireGuard?
Zazwyczaj różnice to 1–2 ms w porównaniu do połączeń bez tunelu. Dla zastosowań infrastrukturalnych i labowych – pomijalne. Dla VoIP lub transmisji w czasie rzeczywistym – również akceptowalne.
9. Czy konfiguracja VLAN-ów i tras OSPF jest ręczna?
Na razie tak, ale planujemy automatyzację. Dzięki prostemu API lub skryptowi możliwe będzie:
- przypisanie kolejnej wolnej podsieci
/30, - utworzenie VLAN na CHR,
- dodanie wpisu do OSPF,
- aktualizacja DNS i monitoringu.
10. Czy można to zintegrować z Proxmox i CI/CD?
Tak. W ramach szkoleń i środowisk testowych planujemy provisioning maszyn w oparciu o API Proxmoxa + wygenerowaną konfigurację VLAN i routingu. Całość będzie integrowalna z Terraformem, Ansible lub autorskim panelem.
11. Jak działa live migration Proxmoxa między lokalizacjami?
Świetnie! Jeśli maszyny proxmox są w jednym klastrze, a routing zapewniony przez OSPF, to VM może być przeniesiona nawet między miastami — bez przerywania pracy. Wystarczy kilka kliknięć i aktualizacja adresu IP.
12. Czy Proxmox z WireGuard i OSPF nadaje się do produkcji?
Tak, pod warunkiem dobrego zaprojektowania. Nasza infrastruktura działa stabilnie z kilkudziesięcioma VM-kami i kilkoma lokalizacjami. Skalowalność, backupy i monitoring są kluczowe. W przypadku klastra rozproszonego (wiele lokalizacji) warto:
- zapewnić niskie opóźnienia i stabilne łącze między węzłami,
- dopasować parametry corosync (np.
token,fail_delay,join,consensus), szczególnie jeśli opóźnienia przekraczają 5–10 ms, - rozważyć separację interfejsu klastra od ruchu maszyn wirtualnych.
13. Czy trzeba mieć publiczne IP w każdej lokalizacji?
Nie. Wystarczy jedno (np. na VPS OVH z Mikrotikiem), by spiąć wszystko WireGuardem. Pozostałe lokalizacje mogą korzystać z NAT i dynamicznego routingu.
14. Jakie narzędzia monitoringowe rekomendujecie?
Zabbix (z agentami lub SNMP), LibreLMS, a także Grafana + Telegraf. Dzięki temu widzimy każdy skok w ruchu, CPU czy BGP/OSPF flappy.
15. Czy to rozwiązanie nadaje się dla małych firm lub instytucji edukacyjnych?
Tak, i to bardzo. Jest tanie w utrzymaniu, elastyczne, łatwe do rozbudowy. A przy tym — w pełni profesjonalne. Jeśli masz kilka serwerów i chcesz je spiąć w jeden logiczny klaster – to rozwiązanie właśnie dla Ciebie.
A jeśli potrzebujesz podobnego rozwiązania...
Na co dzień projektujemy, wdrażamy i utrzymujemy infrastrukturę opartą o:
- Proxmox VE — zarówno lokalnie, jak i w środowiskach rozproszonych,
- Mikrotik CHR i fizyczne routery, w tym IPSec, WireGuard, OSPF, iBGP,
- Linux i wirtualizację — w pełnym zakresie, od routingu, przez sieci overlay, po zarządzanie VM-kami i kontenerami.
Jeśli Twoja firma potrzebuje wsparcia w obszarze sieci, bezpieczeństwa, wirtualizacji lub architektury systemów — zapraszamy do kontaktu.
Lubimy robić rzeczy dobrze.